HTML 파싱 순서 | 봇은 HTML을 어떤 순서로 읽는가
이 글은 "AEO 입문: AI에게 읽히는 기술" 시리즈의 두 번째 글입니다.
1편에서는 검색엔진 봇이 페이지를 발견하고 다운로드하는 크롤링, 그리고 분석해서 데이터베이스에 등록하는 인덱싱의 차이를 다뤘습니다.
이번 글에서는 한 단계 더 들어갑니다.
봇이 다운로드한 HTML 안에서 무엇을 먼저 읽고, 무엇을 중요하게 보고, 무엇을 아예 무시하는지 알아봅니다.

봇은 HTML을 위에서 아래로 읽는다
사람이 웹페이지를 볼 때는 완성된 화면을 봅니다.
예쁜 레이아웃, 이미지, 폰트가 적용된 결과물이죠.
하지만 봇은 다릅니다.
CSS를 적용해서 화면을 그리지 않고, HTML 코드 자체를 위에서 아래로 순서대로 읽으면서 태그 구조와 텍스트만 추출합니다.
이 과정은 크게 세 단계로 나뉩니다.
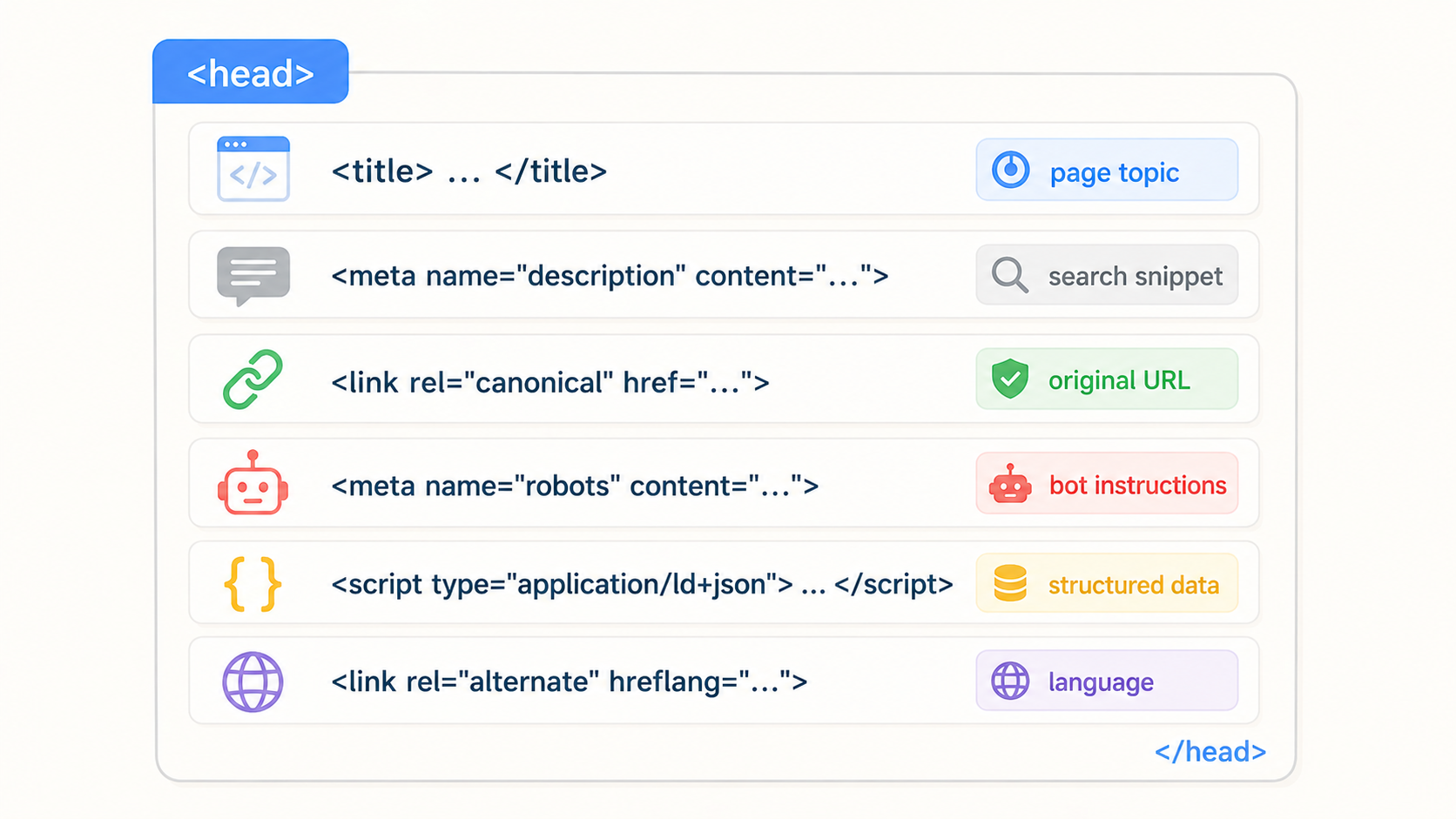
1단계: head 영역 (페이지의 신분증)
봇이 가장 먼저 읽는 곳은 HTML의 <head> 영역입니다.
여기에는 페이지의 기본 정보가 담겨 있습니다.
사람 눈에는 보이지 않지만, 봇에게는 이 페이지가 무엇에 대한 페이지인지 판단하는 첫 번째 근거입니다.
1) title 태그
검색 결과에 파란색 제목으로 표시되는 부분입니다.
봇이 페이지 주제를 판단하는 가장 강력한 신호입니다.
"유기농 현미 선식 500g | 브랜드 A"처럼 핵심 키워드가 포함되어야 합니다.
2) meta description
검색 결과에서 제목 아래에 나오는 회색 설명문입니다.
직접적인 검색 순위 요소는 아니지만, 사용자가 클릭할지 말지를 결정하는 마지막 판단 근거가 됩니다.
같은 순위라도 설명문이 구체적이면 클릭률이 올라갑니다.
다만 Google은 이 설명문을 항상 그대로 보여주지 않습니다.
검색어에 따라 페이지 본문에서 더 관련 있는 문장을 자동으로 뽑아서 대체하기도 합니다.
그래서 meta description을 잘 쓰는 것과 동시에, 본문 텍스트도 잘 구성해야 어느 쪽이 노출되든 손해가 없습니다.
3) canonical 태그
"이 페이지의 원본 주소는 이것입니다"라고 봇에게 선언하는 태그입니다.
같은 상품이 여러 URL로 접근 가능한 경우(카테고리 경유, 검색 경유, 파라미터 붙은 URL 등), canonical 태그가 없으면 봇은 이들을 전부 별개의 페이지로 인식합니다.
하나의 상품에 쏠려야 할 평가가 여러 URL로 분산되는 셈입니다.
이 문제는 시리즈 3편에서 자세히 다룹니다.
4) robots 메타 태그
봇에게 "이 페이지를 인덱싱해라/하지 마라", "링크를 따라가라/따라가지 마라"를 지시하는 태그입니다.
예를 들어 사이트 내부 검색 결과 페이지처럼 인덱싱할 필요가 없는 페이지에는 noindex를 설정합니다.
5) JSON-LD (구조화 데이터)
head 영역에 위치하지만 봇이 별도로 처리하는 특별한 데이터입니다.
"이 페이지는 상품이고, 가격은 얼마이고, 별점은 몇 점"처럼 정형화된 정보를 봇에게 직접 알려줍니다.
이 부분은 시리즈 4편의 핵심 주제입니다.
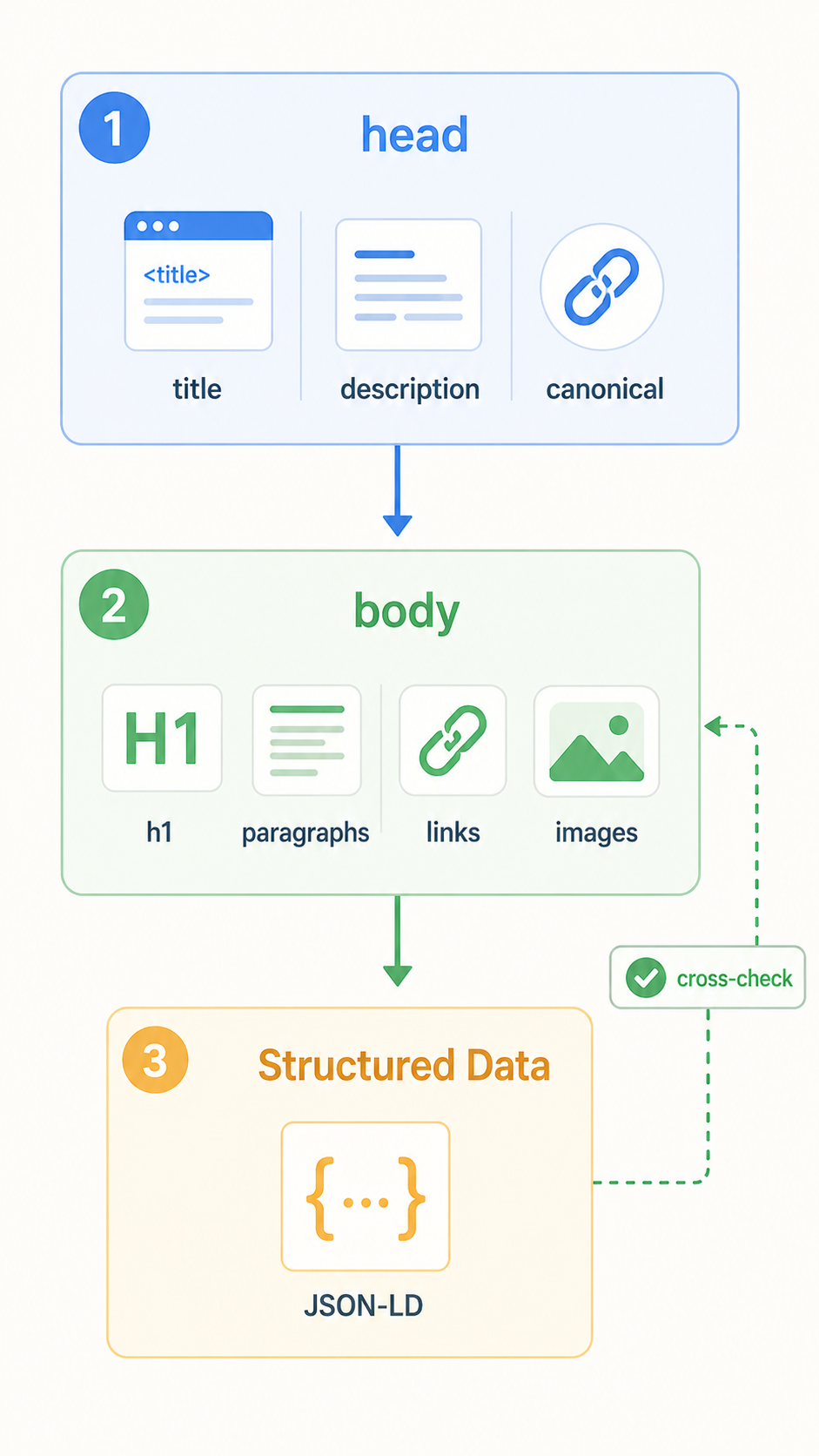
2단계: body 영역 (본문 콘텐츠 분석)
head에서 기본 정보를 수집한 뒤, 봇은 <body> 영역을 위에서 아래로 읽습니다.
이때 봇은 HTML 태그의 의미를 기준으로 중요도를 판단합니다.
1) h1 태그 : 이 페이지의 핵심 주제 선언
봇이 body에서 가장 먼저 주목하는 요소입니다.
"이 페이지는 무엇에 대한 페이지인가"를 h1 태그로 판단합니다.
페이지당 1개가 원칙이고, 페이지 유형마다 다른 내용이 들어가야 합니다.
메인 페이지라면 "브랜드 A — 프리미엄 곡물 선식 공식몰",
카테고리 페이지라면 "곡물 선식 LAB",
상품 상세 페이지라면 "유기농 곡물 선식 500g"처럼
각 페이지의 고유한 주제를 담아야 합니다.
문제는 카페24 같은 쇼핑몰 플랫폼에서 기본 템플릿이 로고에 h1을 거는 경우가 많다는 점입니다.
그러면 메인이든 상품 상세든 카테고리든, 모든 페이지의 h1이 브랜드명 하나로 동일해집니다.
봇 입장에서는 어떤 페이지가 "현미 선식"에 대한 것이고
어떤 페이지가 "귀리 그래놀라"에 대한 것인지 구분할 수 없게 됩니다.
2) h2~h6 태그
소주제 구조입니다. 봇은 이걸로 콘텐츠의 논리적 계층을 파악합니다.
3) p, article, section 태그
본문 텍스트 영역입니다. 키워드가 어떤 맥락에서 사용되었는지를 봇이 여기서 분석합니다.
4) a 태그 (링크)
봇은 링크의 앵커 텍스트를 읽어서 링크가 가리키는 페이지의 주제를 판단합니다.
앵커 텍스트란 클릭 가능한 텍스트 부분을 말합니다.
"유기농 곡물선식 상세보기"라고 쓰면 봇이 링크 대상 페이지의 주제를 파악할 수 있지만,
"여기를 클릭하세요"라고 쓰면 아무런 힌트를 얻지 못합니다.
5) img 태그의 alt 속성
봇은 이미지 자체를 볼 수 없고, alt 텍스트를 읽어서 이미지 내용을 판단합니다.
alt가 비어있으면 봇에게 그 이미지는 존재하지 않는 것과 같습니다.
6) nav, header, footer, aside 태그
봇은 이 태그들로 "여기가 본문이고, 여기는 메뉴이고, 여기는 부가 정보"를 구분합니다.
3단계: 구조화 데이터 — 별도 처리
JSON-LD는 head에 위치하지만, 봇이 HTML 본문과는 별도의 파이프라인으로 처리합니다.
그리고 HTML 본문의 내용과 구조화 데이터의 내용을 서로 대조합니다.
JSON-LD에 가격이 50,000원으로 적혀있는데 본문에는 30,000원이 보인다면,
정보의 신뢰도가 떨어진다고 판단할 수 있습니다.
이 부분은 시리즈 4편에서 본격적으로 다루겠습니다.
봇이 아예 읽지 못하는 4가지
봇이 HTML을 읽는 순서를 알았다면, 반대로 봇이 아예 무시하거나 읽지 못하는 것도 알아야 합니다.
이걸 모르면 "분명히 내용을 넣었는데 왜 검색에 안 잡히지?"라는 상황이 생깁니다.
1) CSS로 숨긴 텍스트display:none이나 visibility:hidden으로 텍스트를 숨기면,
봇은 이를 감지할 수 있고 스팸으로 판단할 수 있습니다.
2000년대에 키워드를 수백 개 넣고 눈에 안 보이게 숨기는 수법이 유행했고,
Google이 이를 스팸 정책으로 규정한 이후로 숨긴 텍스트는 페널티 대상입니다.
2) 이미지 안에 박힌 텍스트
이건 한국 쇼핑몰의 가장 흔한 문제입니다.
상세페이지를 포토샵으로 만든 긴 이미지 한 장으로 구성하면,
사람 눈에는 예쁘지만 봇이 읽을 텍스트가 전혀 없습니다.
AI에게 이 상품은 "정보가 없는 페이지"와 같습니다.
3) iframe 내부 콘텐츠
봇은 iframe의 src를 별도 URL로 취급합니다. 부모 페이지의 콘텐츠로 인식하지 않습니다.
4) 자바스크립트로 동적 생성된 텍스트
1편에서 다뤘던 SPA 문제입니다.
자바스크립트가 실행되기 전에는 HTML에 텍스트가 없으므로,
JS 렌더링을 하지 않는 AI 크롤러에게는 빈 페이지로 보입니다.

쇼핑몰에서 자주 나타나는 문제들
카페24, 고도몰, 아임웹 같은 플랫폼은 서버에서 HTML을 완성해서 보내주기 때문에 SPA 문제는 없습니다.
하지만 위에서 설명한 원리에 기반한 다른 문제들이 있습니다.
1) h1 태그가 로고에 걸려있다.
기본 템플릿에서 로고 이미지를 h1으로 감싸는 경우가 많습니다.
그 결과 상품 상세 페이지에서도 h1이 브랜드명이 되어, 봇이 상품의 고유 주제를 파악하지 못합니다.
카페24는 템플릿 기반이기 때문에 상품 상세 템플릿 하나만 수정하면 전체 상품 페이지에 일괄 반영됩니다.
반대로, 한 곳이 잘못되어 있으면 전체 상품 페이지가 같은 문제를 갖고 있다는 뜻이기도 합니다.
2) 상세페이지가 이미지 한 장이다.
소재, 사이즈, 성분, 사용법 같은 정보가 이미지 안에만 존재합니다.
봇은 이 정보를 읽을 수 없습니다. 최소한 핵심 정보는 HTML 텍스트로 별도 기재해야 합니다.
3) meta title이 상품명 그대로다.
"브랜드 A 에어맥스 270 블랙"처럼 상품명만 title로 사용하면,
봇이 이 페이지의 맥락을 파악하기 어렵습니다.
누구에게 왜 좋은 제품인지, 어떤 검색 의도에 대응하는 페이지인지를 title에 담아야 합니다.
4) canonical 태그가 정리되지 않았다.
같은 상품이 카테고리별, 검색별, 파라미터별로 서로 다른 URL을 가지는데,
canonical이 통일되어 있지 않으면 평가가 분산됩니다.
지금 바로 확인해보세요
내 쇼핑몰 페이지에서 봇이 무엇을 읽고 있는지 확인하는 가장 빠른 방법입니다.
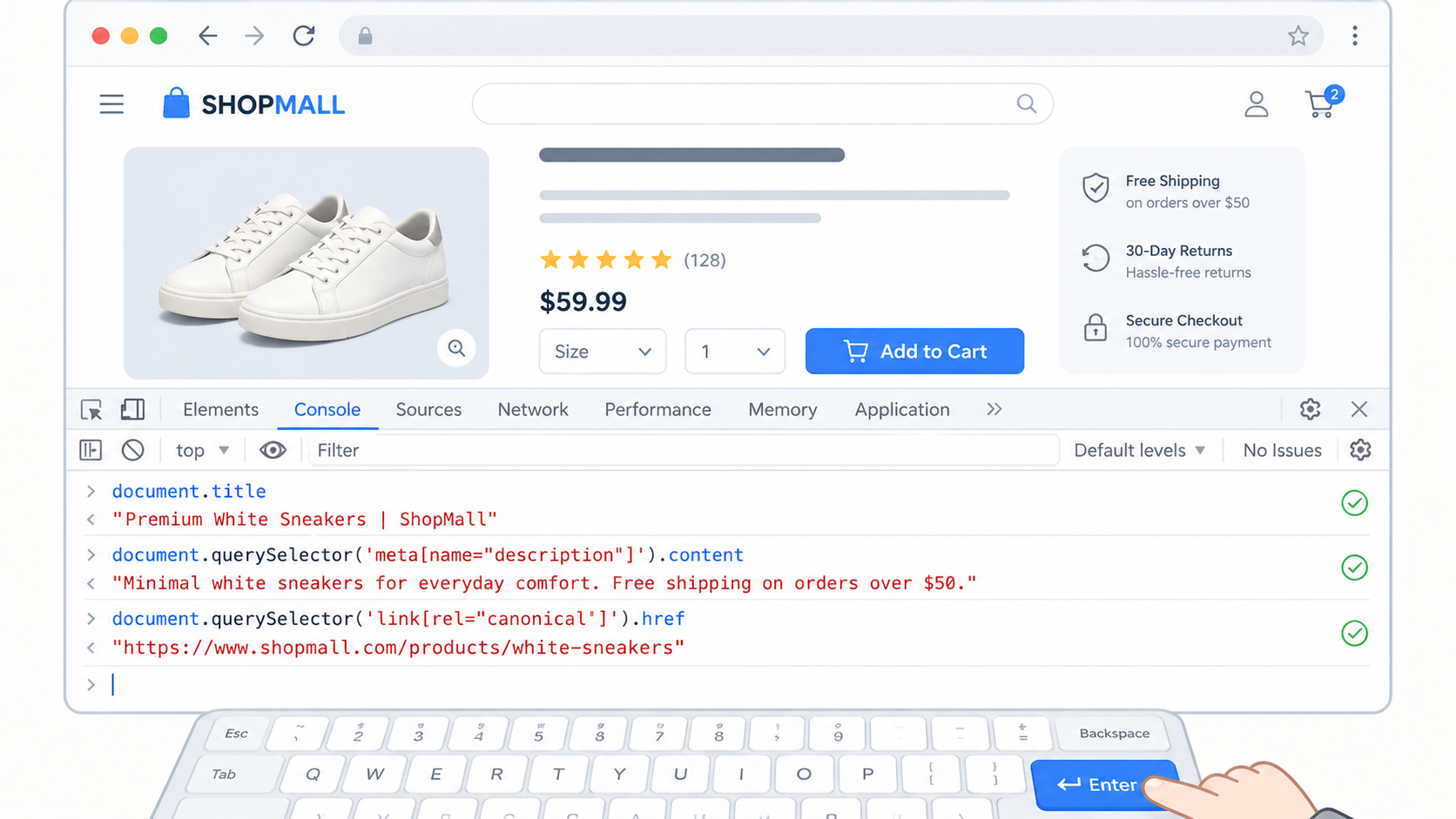
아무 상품 상세 페이지를 열고, 키보드에서 F12를 누르면 개발자 도구가 열립니다.
Console 탭을 선택한 뒤, 아래 코드를 한 줄씩 붙여넣고 Enter를 누르면 됩니다.
1) h1 태그 확인document.querySelectorAll('h1')
결과가 상품명이면 정상입니다.
로고나 브랜드명이 나오면 수정이 필요합니다.
2) meta description 확인document.querySelector('meta[name="description"]')?.content
상품의 핵심 정보가 담겨있으면 좋습니다.
빈 값이거나 "다양한 상품을 만나보세요" 같은 기본 문구가 나오면 개선이 필요합니다.
3) canonical 태그 확인document.querySelector('link[rel="canonical"]')?.href
같은 상품을 카테고리 경유, 직접 접근, 검색 경유로 각각 열어서 이 코드를 실행해보세요.
세 결과가 모두 같은 URL을 가리키면 정상입니다. 다르면 중복 콘텐츠 문제가 있는 것입니다.
다음 글에서는 봇이 사이트에 방문하기 전에 가장 먼저 확인하는 두 파일, robots.txt와 sitemap.xml에 대해 다루겠습니다.