robots.txt | AI 봇에게 문을 열어주는 법
이 글은 "AEO 입문: AI에게 읽히는 기술" 시리즈의 세 번째 글입니다.
1편에서는 크롤링과 인덱싱의 차이를, 2편에서는 봇이 HTML을 어떤 순서로 읽는지를 다뤘습니다.
이번 글에서는 봇이 사이트에 도착했을 때 가장 먼저 확인하는 파일, robots.txt에 대해 알아봅니다.

robots.txt가 뭔가요?
봇이 내 사이트에 도착하면 페이지를 크롤링하기 전에 가장 먼저 확인하는 파일이 있습니다. 바로 robots.txt입니다.
이 파일은 웹사이트의 루트(최상위)에 위치하는 텍스트 파일이고, 주소는 항상 동일합니다. https://내도메인.com/robots.txt로 접근하면 누구나 볼 수 있습니다.
역할은 간단합니다. 봇에게 "이 경로는 와도 돼, 이 경로는 오지 마"라고 안내하는 것입니다.
1편에서 배운 크롤링 흐름을 떠올려보면, 봇은 URL을 발견한 뒤 robots.txt를 먼저 확인하고, 허용된 경로면 크롤링을 진행하고, 차단된 경로면 그 페이지를 건너뜁니다.
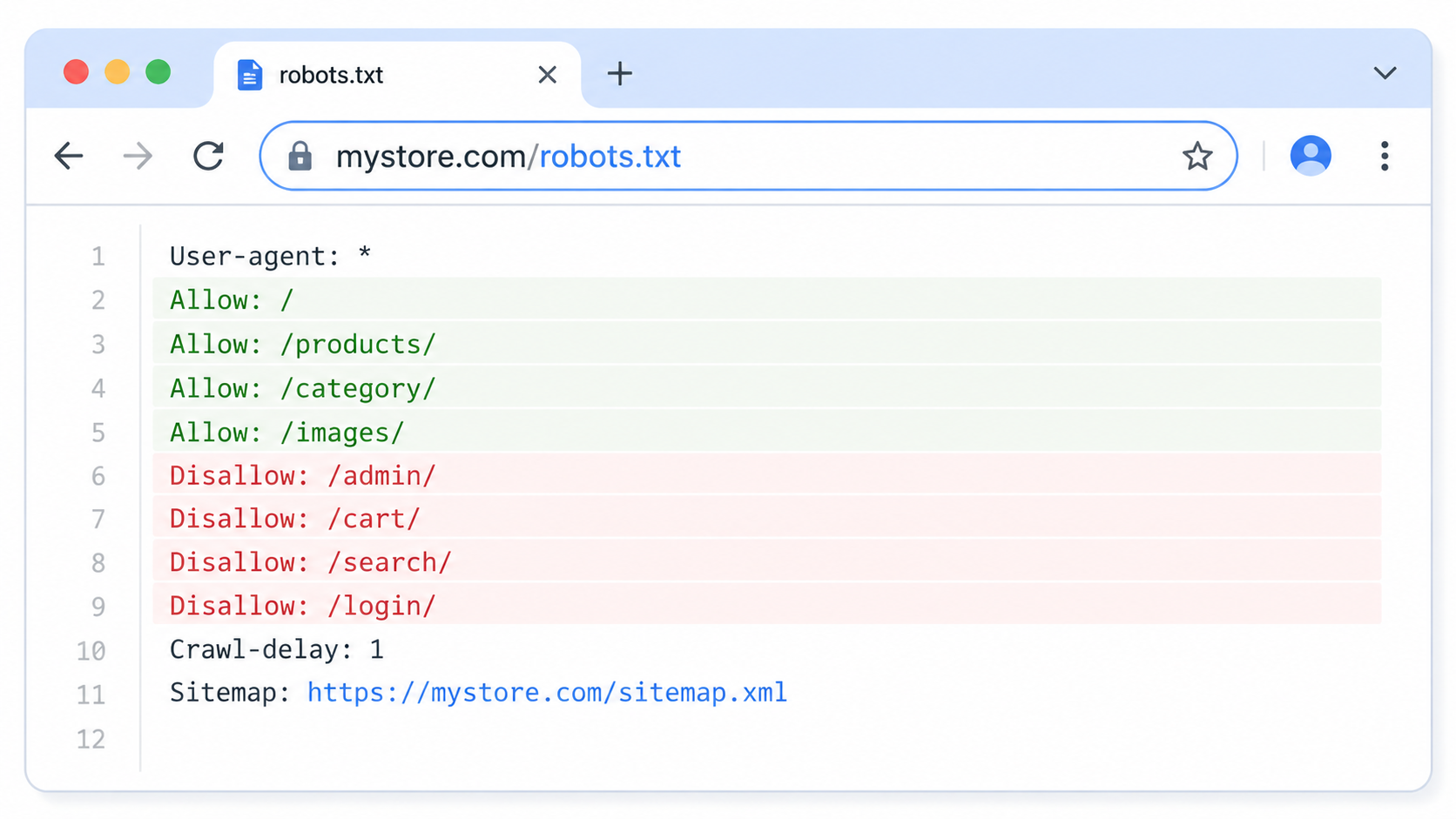
기본 문법은 이렇습니다
robots.txt의 구조는 매우 단순합니다.
User-agent: *는 "모든 봇에게 적용"이라는 뜻입니다. 특정 봇만 지정하고 싶으면 User-agent: Googlebot처럼 이름을 넣을 수 있습니다.
Disallow: /admin/은 "/admin/ 하위 경로는 크롤링하지 마"라는 지시입니다.
Allow: /는 "나머지는 전부 크롤링 허용"입니다.
Sitemap: https://내도메인.com/sitemap.xml은 사이트맵 파일의 위치를 봇에게 알려주는 줄입니다.
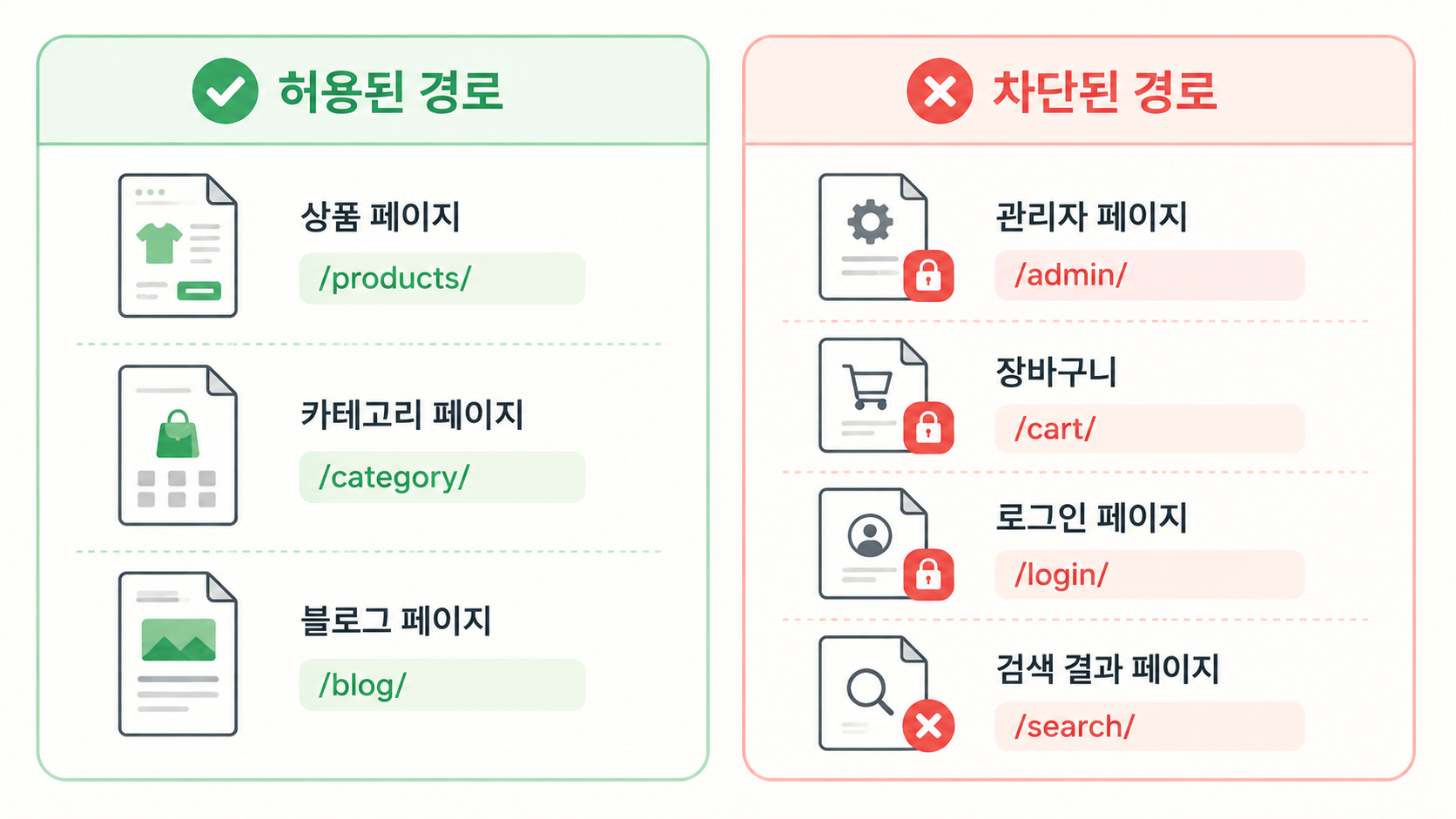
쇼핑몰에서 차단해야 하는 경로들
모든 페이지를 봇에게 열어줄 필요는 없습니다. 크롤링해봐야 의미가 없거나, 오히려 문제를 일으키는 경로가 있습니다.
관리자/회원 영역. 로그인, 회원가입, 관리자 페이지는 봇이 크롤링할 이유가 없습니다. 보안상으로도 노출되지 않는 것이 좋습니다.
주문/결제 페이지. 장바구니, 결제 페이지가 검색 결과에 나타나면 안 됩니다.
내부 검색 결과 페이지. 사이트 내부 검색은 검색어 조합이 무한대에 가깝습니다. 이걸 전부 크롤링하면 같은 상품 목록이 수십, 수백 개의 URL로 중복 생성됩니다.
추적 파라미터가 붙은 URL. utm 같은 마케팅 추적 파라미터가 붙은 URL은 내용은 같지만 주소가 다르므로, 봇이 별개 페이지로 인식할 수 있습니다.
많이 하는 오해: 차단했다고 비공개가 아닙니다
robots.txt에서 흔히 오해하는 것이 하나 있습니다. Disallow를 걸면 그 페이지가 비공개가 된다고 생각하는 것입니다.
그렇지 않습니다. robots.txt는 봇에게 "크롤링하지 말아달라"는 요청일 뿐이고, URL을 직접 입력하면 누구나 접근할 수 있습니다. Google 같은 정상적인 봇은 이 요청을 존중하지만, 악의적인 크롤러는 무시할 수 있습니다.
또 한 가지, Disallow를 걸어도 해당 페이지가 인덱싱될 수 있습니다. 봇이 직접 크롤링하지 않더라도, 외부 사이트에서 해당 URL로 링크를 걸고 있으면 간접 정보만으로 인덱싱하는 경우가 있습니다. 확실하게 인덱싱을 막으려면 robots.txt가 아니라 해당 페이지의 HTML에 <meta name="robots" content="noindex">를 넣어야 합니다.
정리하면, robots.txt는 "크롤링 제어"이고 noindex는 "인덱싱 제어"입니다. 목적이 다릅니다.
AI 크롤러를 차단할 것인가, 열어줄 것인가
최근 AI 크롤러와 관련해서 논쟁이 되는 주제가 있습니다. ChatGPT의 GPTBot, Perplexity의 PerplexityBot, Claude의 ClaudeBot 같은 AI 크롤러를 robots.txt로 차단할 것인가?
대형 언론사나 출판사는 저작권 보호 목적으로 AI 크롤러를 차단하는 경우가 많습니다. 자기 콘텐츠가 AI 학습 데이터로 사용되는 것을 원치 않기 때문입니다.
하지만 AI 검색에 내 상품이 노출되기를 원하는 쇼핑몰이라면, 이야기가 다릅니다. AI 크롤러를 차단하면 ChatGPT나 Perplexity가 "운동화 추천해줘"라는 질문에 답할 때 내 사이트의 상품 정보를 참고할 수 없게 됩니다. AEO를 하려는 커머스 입장에서는 AI 크롤러의 접근을 열어두는 것이 맞습니다.
컨설팅 관점에서 보면, 클라이언트 사이트의 robots.txt를 열어봤을 때 AI 크롤러가 차단되어 있다면 바로 짚어줄 수 있는 포인트가 됩니다.

카페24/고도몰에서는 어떻게 확인하나요?
카페24는 기본 robots.txt를 자동 생성해줍니다. https://쇼핑몰주소/robots.txt로 직접 접근하면 내용을 확인할 수 있습니다.
문제는 기본 제공 내용이 최적화되어 있지 않은 경우가 많다는 점입니다. 장바구니, 결제, 검색 결과 경로가 Disallow 되어 있지 않으면, 봇이 불필요한 페이지까지 전부 크롤링하게 됩니다.
수정은 카페24 관리자 페이지의 스마트디자인 편집기에서 할 수 있습니다. 고도몰, 아임웹도 각 플랫폼의 관리자 메뉴에서 robots.txt를 편집할 수 있습니다.
지금 바로 확인해보세요
내 사이트의 robots.txt를 확인하는 방법은 아주 간단합니다. 브라우저 주소창에 https://내도메인.com/robots.txt를 입력하면 됩니다.
열어본 뒤 아래 네 가지를 확인해보세요.
Disallow에 관리자, 장바구니, 주문, 검색 경로가 포함되어 있는지. 없으면 봇이 불필요한 페이지를 크롤링하고 있는 것입니다.
상품 페이지나 카테고리 페이지가 실수로 차단되어 있지는 않은지. 간혹 Disallow 범위를 너무 넓게 잡아서 정작 봇이 읽어야 할 상품 페이지까지 막아버리는 경우가 있습니다.
AI 크롤러(GPTBot, PerplexityBot, ClaudeBot)가 차단되어 있지는 않은지. AI 검색 노출을 원한다면 이 봇들은 열어두어야 합니다.
Sitemap 경로가 명시되어 있는지. Sitemap 줄이 없으면 봇이 사이트맵을 자동으로 찾지 못할 수 있습니다. 다음 글에서 이 sitemap.xml에 대해 자세히 다루겠습니다.